
A saída é a multiplexação. Multiplexar é apenas outra forma de dizer compartilhar. A idéia é: em vez de limitar a utilização de um par de fios para um chamada de cada vez, vamos usar o mesmo par de fios (ou outros meios de transmissão) para várias chamadas simultâneas.
Aqui temos que fazer um parêntese matemático. Nada muito complicado, e nenhuma conta pra fazer. Appenas o entendimento de alguns conceitos. Mas se você não entender isto aqui, muita coisa mais tarde vai parecer bruxaria.
O sinal elétrico analógico (tensão ou corrente) que representa a voz do usuário participante de uma chamada telefônica pode ser descrito como uma função do tempo. Em 1807 Joseph Fourier demonstrou que qualquer função pode ser decomposta na forma de uma série infinita de funções seno e cosseno (isto também pode ser visto como funções exponenciais complexas, mas deixa isso pra lá...). Este tipo de série foi batizada série de Fourier, em sua homenagem. A figura abaixo dá alguns exemplos (parciais) da decomposição de algumas funções em série de Fourier.
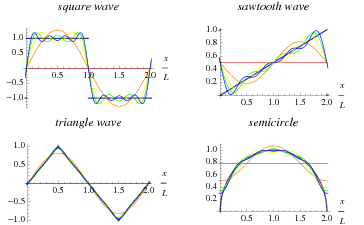
Com isto temos uma forma alternativa para representar funções no tempo. Podemos representá-las através da amplitude de cada um dos termos da sua decomposição em série de Fourier. Ou seja: uma função tensão (ou corrente) x tempo pode ser expressa por uma função equivalente amplitude x frequência. Exemplo: a figura abaixo é o gráfico de um sinal elétrico em função do tempo medido na saída de um microfone (repare que a tensão é proporcional à pressão do ar gerada pelas ondas sonoras captadas pelo microfone).

Quando obtemos a sua decomposição em série de Fourier, através de um processo chamado de transformada de Fourier, obtemos o seguinte gráfico de amplitude em função da frequência.

Então observamos que o nosso sinal originl é possui apenas duas componentes, uma com frequência de 4 Hz e amplitude 1 V (no caso) e outra com frequência de 12 Hz e amplitude aproximada de 0,3 V. O primeiro gráfico é conhecido como a representação do sinal no domínio tempo, e o segundo como a representação do sinal no domínio frequência. O segundo gráfico também é conhecido como o espectro de frequências do sinal representado no primeiro gráfico. Fim do parêntese (outros virão mais tarde).
Suponha agora que nós temos um sinal arbitrário s(t) cuja rpresentação no domínio frequência seja algo parecido com a figura abaixo.

A conversão entre a frequência f (expressa em Hertz) e a frequência angular w (ômega minúsculo, expressa em radianos/segundo) é dada pela fórmula:

Agora vamos considerar um sinal C(t), puramente senoidal, que, só por conveniência, vamos representar por uma função cosseno. Vamos tomar a nossa origem no temo de tal forma que a fase deste sinal seja igual a zero. Então, no domínio frequência, temos o seguinte:

Vamos agora fazer que a amplitude do sinal C(t) (portadora ou carrier) varie em função do sinal s(t). Desta forma obtemos um sinal modulado em amplitude (amplitude modulated ou AM). No domínio tempo temos algo parecido com o mostrado na figura abaixo (onde s(t) é um sinal senoidal puro)
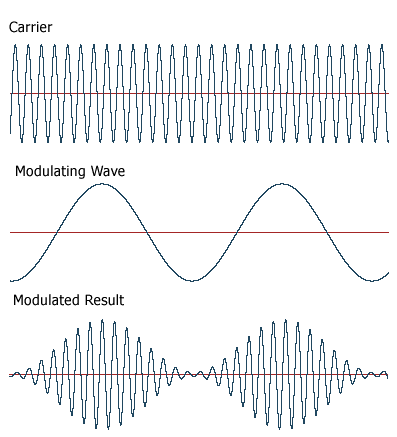
O nosso sinal AM tem a seguinte aparência no domínio frequência:

Reparem que o nosso sinal original teve seu espectro de frequência trasladado da origem para a frequência da portadora. Então podemos fazer o seguinte esquema:

Este é o auge da tecnologia analógica para a transmissão de sinais entre as centrais de comutação. FDM significa frequency division multiplexing, e como pode ser visto na figura, a multiplexação é feita pela modulação AM dos vários sinais de entrada, cada um deles modulando portadoras separadas em frequência de tal forma que os espectros individuais não se sobreponham após a translação. Na outra ponta do circuito cada sinal individual pode ser separado do sinal multiplexado M(t) usando filtros passa-faixa centrados na frequência de cada portadora.
Daqui em diante os avanços tecnológicos ocorreram na digitalização da comutação e da transmissão de sinais entre as centrais de comutação. Trataremos disto na parte 2 deste artigo.













